Web Scraping con NextJS API routes y puppeteer
Previamente
Antes tenía una web que me listaba tiendas Tambo+ y las ordenaba según la que esté más cerca a mi, ésto gracias a un endpoint que encontré en su propia página https://tambomas.pe/public/api/stores pero lamentablemente ya no puedo acceder a ese endpoint.
Al acceder a su página oficial, que ha tenido un rediseño, me di cuenta que tienen una página https://www.tambo.pe/institucional/tiendas donde tienen la lista de todas sus tiendas por eso decidí hacer web scrapping.
Empezamos
En primer lugar tenemos que tener nuestra aplicación con NextJS lista y como dice el título usaremos puppeteer asi que lo instalamos en nuestras dependencias.
yarn add puppeteer
NextJS nos permite tener endpoints simplemente creando archivos que estén dentro de pages/api/. En este caso creamos uno que se llame stores.js.
import puppeteer from "puppeteer";
export default async (req, res) => {
try {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto("https://www.tambo.pe/institucional/tiendas");
const result = await page.evaluate(() => {
const list = document.querySelectorAll(
"[class^=styles__FaqAnswerContainer]"
);
const data = {};
[...list].forEach((group) => {
const district = group.firstElementChild.children;
[...district].forEach((element, index) => {
if (element.classList.contains("id-tienda")) {
const id = element.innerText.trim();
// Sometimes link is on another div
let gmapLink;
if (district[index + 4].firstElementChild !== null) {
gmapLink = district[index + 4].firstElementChild.href;
} else {
gmapLink = district[index + 5].firstElementChild.href;
}
// Sometimes address is on another div
let address;
if (district[index + 2].innerText.length > 6) {
address = district[index + 2].innerText;
} else {
address = district[index + 3].innerText;
}
const obj = {
id,
name: district[index + 1].innerText,
address,
gmapLink,
};
data[id] = obj;
}
});
});
return data;
});
browser.close();
res.statusCode = 200;
res.json({
data: Object.values(result),
});
} catch (err) {
res.statusCode = 404;
res.json({ data: { error: err.message } });
}
};
La primera parte nos sirve para inicializar puppeteer, abrir el navegador e ir a la página que queremos
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto("https://www.tambo.pe/institucional/tiendas");
Luego puppeteer tiene una función que nos ayuda a encontrar elementos en la página, que es justo lo que queremos, con page.evaluate().
Dentro de esa función empezamos a encontrar los elementos que contienen la data que queremos para almacenarla en una variable data, que es la que vamos a retornar al final en un json para nuestro endpoint.
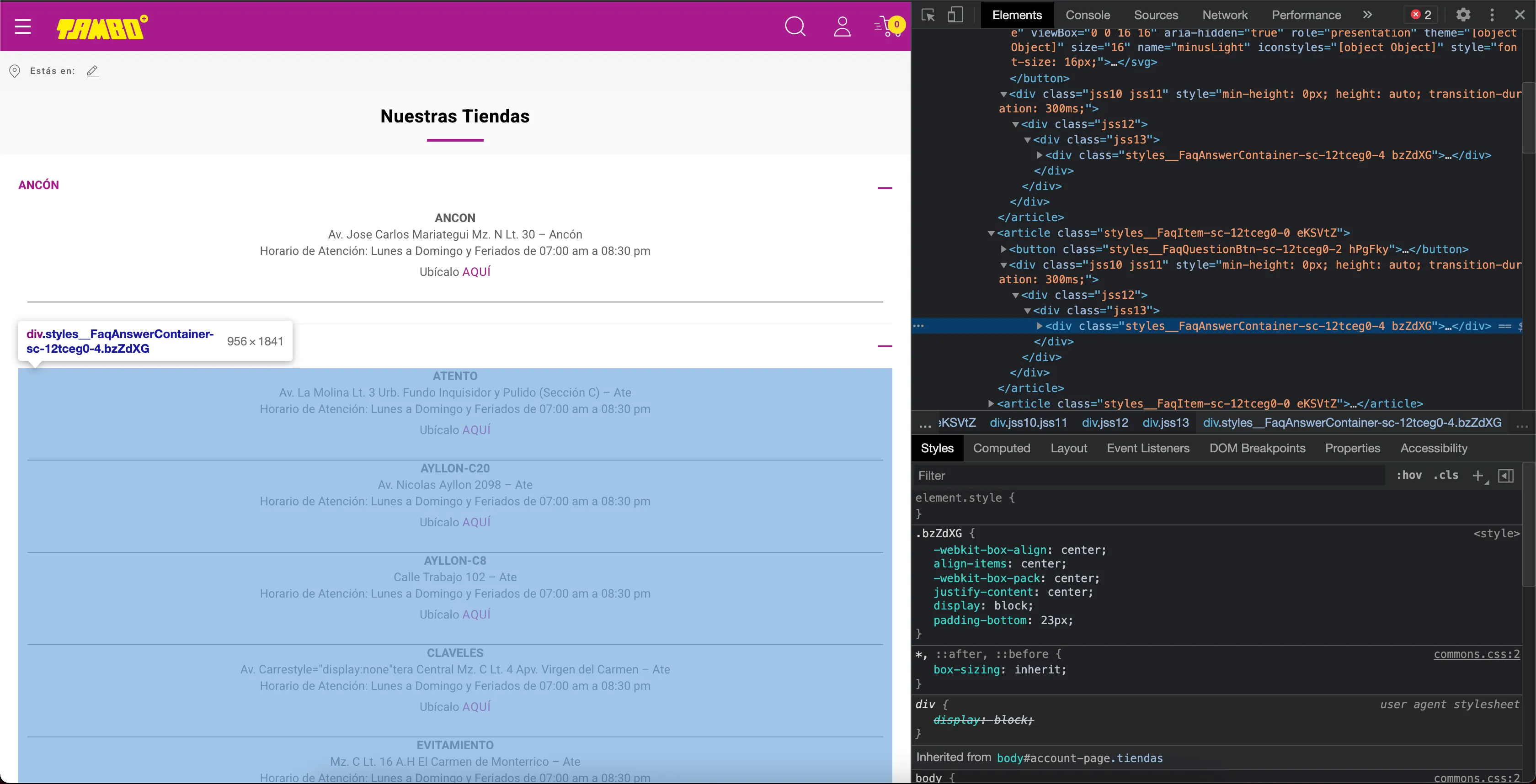
Como vemos en la imagen el div contenedor del grupo de tiendas por distrito tiene una clase generada que empieza con styles__FaqAnswerContainer, por lo tanto usamos el siguiente query para obtenerlos.
document.querySelectorAll("[class^=styles__FaqAnswerContainer]");
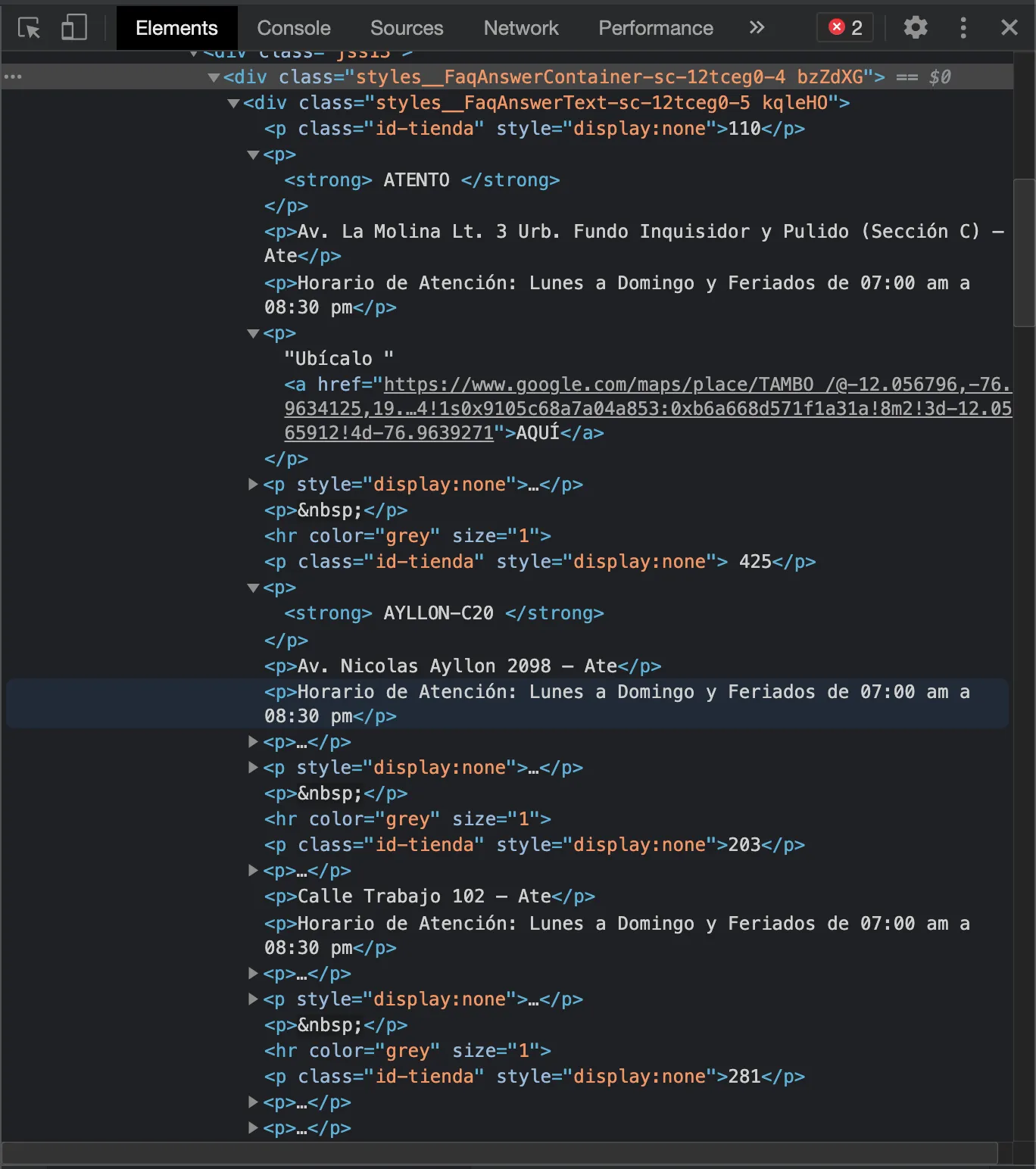
Cómo pueden ver la estructura en sí de las tiendas individuales está dificil de determinar debido a que no tienen un elemento que los contenga, si no que están todos dispersos dentro del mismo div. Lo primero que se me ha ocurrido hasta ahora es encontrar los elementos que tienen una clase id-tienda que contiene el id de la tienda y me sirve como separador entre una tienda de la siguiente.
if (element.classList.contains("id-tienda")) {
const id = element.innerText.trim();
// Sometimes link is on another div
let gmapLink;
if (district[index + 4].firstElementChild !== null) {
gmapLink = district[index + 4].firstElementChild.href;
} else {
gmapLink = district[index + 5].firstElementChild.href;
}
// Sometimes address is on another div
let address;
if (district[index + 2].innerText.length > 6) {
address = district[index + 2].innerText;
} else {
address = district[index + 3].innerText;
}
const obj = {
id,
name: district[index + 1].innerText,
address,
gmapLink,
};
data[id] = obj;
}
Al encontrar el elemento que contiene el id nos damos cuenta que el elemento siguiente es el que contiene el nombre de la tienda. Luego el siguiente al nombre suele ser la dirección en algunos casos pero en otros no, al igual con el link a Google Maps, es por eso que hay unos condicionales para esos atributos.
Un poco complicado conseguir la data pero lo logramos 🎉.
Ahora levantamos nuestra aplicación NextJS usando yarn dev y visitamos http://localhost:3000/api/stores
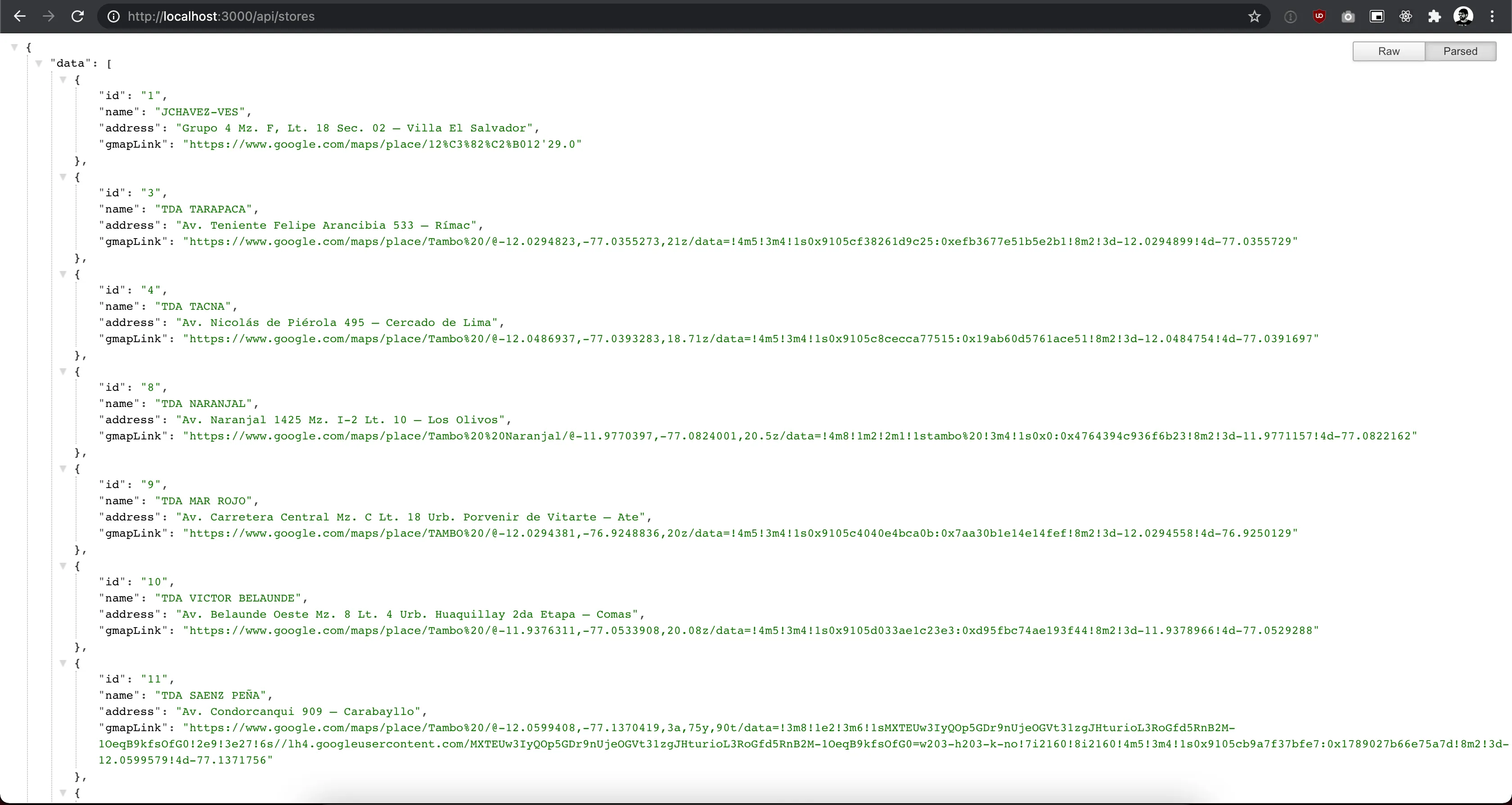
Extra
Tuve algunos problemas publicando la aplicación en vercel debido a que puppeteer no encuentra el navegador. Para esto hacemos algunos cambios en las opciones de puppeteer.
Instalamos puppeteer-core en lugar de puppeteer y chrome-aws-lambda
yarn add puppeteer-core chrome-aws-lambda
import puppeteer from "puppeteer-core";
import chrome from "chrome-aws-lambda";
const exePath =
process.platform === "win32"
? "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe"
: process.platform === "linux"
? "/usr/bin/google-chrome"
: "/Applications/Google Chrome.app/Contents/MacOS/Google Chrome";
async function getOptions() {
let options;
if (process.env.NODE_ENV !== "production") {
options = {
args: [],
executablePath: exePath,
headless: true,
};
} else {
options = {
args: [...chrome.args, "--hide-scrollbars", "--disable-web-security"],
defaultViewport: chrome.defaultViewport,
executablePath: await chrome.executablePath,
headless: true,
ignoreHTTPSErrors: true,
};
}
return options;
}
Con process.env.NODE_ENV !== "production" estamos detectando si estamos corriendo en local para usar chrome de nuestro equipo.
De esta manera obtenemos las opciones que debemos pasar a puppeteer
const options = await getOptions();
const browser = await puppeteer.launch(options);